ソース: Release Release v3.20.1 · RooCodeInc/Roo-Code
[3.20.1] – 2025-06-12
- Bedrockモデルの思考サポートを一時的に元に戻します
- MCP実行ブロックのパフォーマンスを改善します
- チャットビューにインデックス作成ステータスバッジを追加します
———
個人メモ
元に戻す / revert の判断が早いw
(実験サイトでのブログなのでサイトが落ちてたらごめんなさい)
ソース: Release Release v3.20.1 · RooCodeInc/Roo-Code
元に戻す / revert の判断が早いw
ソース: Release Release v3.20.0 · RooCodeInc/Roo-Code
マーケットプレイスが実験的に追加されたようですね。 実験的なので、デフォルト OFF でしたので、
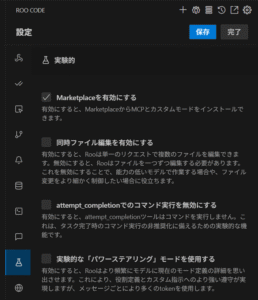
のように、
実験的 -> Marketplaceを有効にする で有効に変更後、保存すると、上部に vscode の拡張機能アイコンと同じようなものが表示され、Marketplace から MCP サーバの導入などが行えるようになりました。
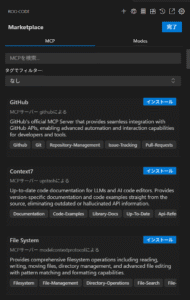
こちらは本家 Cline との大きな差で、MCP 関連のユーザビリティの差になっていたので、非常に頼もしいアップデートですね。
ソース: Release Release v3.19.6 · RooCodeInc/Roo-Code
v3.19.5 はリリースを見送られたみたいですね。念の為。
元論文: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
数学的推論は、人工知能にとって最も困難な分野の1つであり続けています。最近の大規模言語モデル(LLM)は、幅広いタスクにわたって目覚ましい能力を発揮していますが、数学におけるパフォーマンスは一般的に人間の専門家に遅れをとっています。最近リリースされたDeepSeekMathモデルは、この分野における大きな進歩を表しており、オープンソースAIモデルが数学的問題解決において達成できることの限界を押し広げています。
DeepSeekMathは、清華大学および北京大学の研究者との共同研究により、DeepSeek-AIによって開発された特殊な言語モデルです。研究チームは、難解なMATHデータセット(競技レベルの数学問題のコレクション)で50%以上の精度を達成し、数学的推論タスクにおいて以前のオープンソースモデルに匹敵するだけでなく、多くの場合それを上回るモデルを作成しました。
 図1:MATHベンチマークにおけるDeepSeekMath-7Bと以前のモデルとのパフォーマンス比較。既存のオープンソースモデルからの劇的な改善を示し、GPT-4のようなクローズドソースモデルのパフォーマンスに近づいています。
図1:MATHベンチマークにおけるDeepSeekMath-7Bと以前のモデルとのパフォーマンス比較。既存のオープンソースモデルからの劇的な改善を示し、GPT-4のようなクローズドソースモデルのパフォーマンスに近づいています。
数学的推論は、AIシステムに独自の課題をもたらします。パターン認識や統計的相関から恩恵を受けることができる多くの自然言語タスクとは異なり、数学は正確な論理的推論、段階的な演繹、および問題を解決するための抽象的な概念の適用を必要とします。これらの特性は、数学的推論をAIシステムの真の知性と推論能力の特に厳格なテストにします。
ごく最近まで、この分野はGPT-4やGemini-Ultraのようなクローズドソースモデルによって支配されており、オープンソースの代替案は大幅に遅れをとっていました。この格差は、独自のソリューションに頼ることができない研究者、教育者、および学生にとって、高性能な数学AIシステムへのアクセスを制限していました。
DeepSeekMathの研究は、いくつかの重要な方法でオープンソースの数学AIを進歩させることによって、このギャップに対処します。
DeepSeekMathの成功の要は、そのトレーニングデータセットです。研究者らは、Webから抽出された数学コンテンツの特殊なコレクションであるDeepSeekMathコーパスを開発しました。コーパスは、革新的な反復パイプラインを通じて作成されました。
 図2:DeepSeekMathコーパス構築のための反復パイプライン。継続的に改善されるfastText分類器を用いて、Common Crawlから数学的コンテンツを抽出する方法を示しています。
図2:DeepSeekMathコーパス構築のための反復パイプライン。継続的に改善されるfastText分類器を用いて、Common Crawlから数学的コンテンツを抽出する方法を示しています。
このアプローチの有効性は、既存の数学的データセットに対する包括的なベンチマークで実証されています。図3に示すように、DeepSeekMathコーパスは、GSM8K、MATH、CMATH、BBHを含む複数の数学的ベンチマークにおいて、他のデータセット(MathPile、OpenWebMath、Proof-Pile-2)を一貫して上回っています。
 図3:異なる数学的データセットで訓練されたモデルのパフォーマンス比較。DeepSeekMathコーパスがさまざまなベンチマークで優れたパフォーマンスを示すことを示しています。
図3:異なる数学的データセットで訓練されたモデルのパフォーマンス比較。DeepSeekMathコーパスがさまざまなベンチマークで優れたパフォーマンスを示すことを示しています。
DeepSeekMathモデルは、コードと一般的な言語タスクですでに訓練された70億パラメータのモデルであるDeepSeek-Coder-Base-v1.5を基盤として構築されています。研究者たちは、コードに関する事前の訓練が数学的推論に著しい恩恵をもたらすという重要な発見をしました。この発見は、コーディング能力と数学的な問題解決能力との関係について、AIコミュニティで長年議論されてきた問題に対処するものです。
トレーニングプロセスは、主に次の3つの段階で構成されています。
事前学習: DeepSeekMathコーパス、コード、および一般的な言語データを使用して、ベースモデルをさらにトレーニングします。
教師ありファインチューニング(SFT):事前学習済みのモデルを、ソリューション付きの厳選された数学的な問題のデータセットでファインチューニングしました。さまざまな推論形式を取り入れています。
強化学習: SFTモデルは、Group Relative Policy Optimization(GRPO)と呼ばれる新しい強化学習アプローチを使用してさらに最適化されました。
DeepSeekMathの研究における重要な革新は、LLMのファインチューニングのために特別に設計された、メモリ効率の高い強化学習アルゴリズムであるGRPOの開発です。GRPOは、Proximal Policy Optimization(PPO)のような人間からのフィードバックによる従来の強化学習(RLHF)アプローチの主な制限の1つである、価値モデルを維持するための高いメモリ要件に対処します。
 図4:従来のPPOと新しいGRPOアプローチの比較。GRPOは、入力ごとに複数の出力を生成し、グループ内の相対的なパフォーマンスに基づいてアドバンテージを計算することにより、価値モデルの必要性を排除します。
図4:従来のPPOと新しいGRPOアプローチの比較。GRPOは、入力ごとに複数の出力を生成し、グループ内の相対的なパフォーマンスに基づいてアドバンテージを計算することにより、価値モデルの必要性を排除します。
GRPOの仕組みは次のとおりです。
このアプローチは、個別の価値モデルの必要性を排除し、パフォーマンスを維持または向上させながら、メモリ要件を削減します。研究者たちはまた、オンライン強化学習(報酬モデルが継続的に更新される)がオフラインアプローチよりも優れていることを実証しました。
# GRPO の簡略化された擬似コード
def GRPO_update(policy_model, reference_model, reward_model, batch):
for query in batch:
# 各クエリに対して複数の出力を生成する
outputs = [policy_model.generate(query) for _ in range(G)]
# すべての出力に対する報酬を計算する
rewards = [reward_model(query, output) for output in outputs]
# 参照モデルからの KL ダイバージェンスを計算する
kl_penalties = [compute_kl(output, reference_model) for output in outputs]
# 調整された報酬を計算する
adjusted_rewards = [r - beta * kl for r, kl in zip(rewards, kl_penalties)]
# グループ内のアドバンテージを計算する
mean_reward = sum(adjusted_rewards) / len(adjusted_rewards)
advantages = [r - mean_reward for r in adjusted_rewards]
# アドバンテージに基づいてポリシーを更新する
for output, advantage in zip(outputs, advantages):
policy_model.update(query, output, advantage)DeepSeekMath モデルは、包括的な数学ベンチマークセットで評価されました。
DeepSeekMath-Instruct 7B は、次のような目覚ましい成果を上げています。
反復的な強化学習プロセスは、図 5 に示すように、トレーニングの反復を通じて継続的な改善を示しています。
 図 5: GSM8K および MATH ベンチマークにおける強化学習の反復によるパフォーマンスの向上。各反復で一貫した改善が見られます。
図 5: GSM8K および MATH ベンチマークにおける強化学習の反復によるパフォーマンスの向上。各反復で一貫した改善が見られます。
特に興味深い発見は、モデルが複数の解を生成し、多数決を行う Majority-at-K (Maj@K) のパフォーマンスの向上によって示されるように、RL がモデルの出力分布のロバスト性を大幅に向上させることです。
 図 6: 強化学習の前後の多数決 (Maj@K) と pass@K メトリクスのパフォーマンス比較。RL トレーニング後にロバスト性が向上しています。
図 6: 強化学習の前後の多数決 (Maj@K) と pass@K メトリクスのパフォーマンス比較。RL トレーニング後にロバスト性が向上しています。
DeepSeekMath の研究により、LLM における数学的推論についていくつかの重要な洞察が得られました。
データの品質は量に勝る: DeepSeekMath コーパスは、いくつかの代替案よりも小さいものの、高品質の数学コンテンツを提供し、パフォーマンスの向上につながります。これは、的を絞った高品質のデータは、単にデータセットのサイズを増やすよりも価値があるという原則を裏付けています。
コードトレーニングは数学に役立つ: 数学の微調整の前にコードで事前トレーニングされたモデルは、数学的推論タスクで著しく優れたパフォーマンスを発揮します。これは、プログラミングと数学の問題解決の間で共有される認知メカニズムを示唆しています。
arXiv は万能薬ではない: 一般的な考えに反して、arXiv 論文でトレーニングしても、この研究で使用されたベンチマークデータセットで目立った改善は見られませんでした。これは、学術論文が数学 AI モデルのトレーニングに理想的であるという仮定に異議を唱えています。
プロセス監視は結果監視よりも優れている: RL の報酬モデルをトレーニングする場合、問題解決プロセス (ソリューションがどのように導き出されるか) を監視する方が、最終的な答えを評価するよりも効果的です。
オンライン RL はオフライン RL よりも優れている: 強化学習中に報酬モデルを継続的に更新すると、固定されたままにするよりも優れたパフォーマンスにつながり、適応学習アプローチの利点が強調されます。
この研究では、比較的小規模なモデル(70億パラメータ)でも、適切なデータと最適化手法でトレーニングすれば、競争力のある性能を達成できることが示されています。これは、強力な数学的推論能力を実現するために、必ずしも非常に大規模なモデルが必要ではないことを示唆しています。
DeepSeekMathは、さまざまな分野で多くの潜在的な応用が可能です。
教育: 小学校から大学数学まで、さまざまなレベルの学生に、パーソナライズされた個別指導や問題解決の支援を提供します。
研究: 数学者や科学者が、複雑な数学的概念を探求し、証明や解決策を生成するのを支援します。
工学と科学: 数学的モデリングに大きく依存する、物理学、工学、経済学などの分野での問題解決をサポートします。
アクセシビリティ: 高価な独自モデルへのアクセスがない個人や組織が、高度な数学支援を利用できるようにします。
特定の応用以外にも、DeepSeekMathは、より一般的なAI推論能力に向けた重要な一歩となります。数学的推論は、より広範な論理的思考および分析的思考の代用となり、この分野の改善は、AI推論全般に恩恵をもたらす可能性があります。
DeepSeekMathは、データ品質、特殊な事前トレーニング、革新的な強化学習技術に注意を払うことで、オープンソースのAIモデルが数学的推論において競争力のある性能を達成できることを示しています。このモデルの開発アプローチは、AI推論能力をより広範に改善するための貴重な洞察を提供します。
この研究は、数学AIを進歩させるための3つの重要な要素を強調しています。
オープンソースモデルとして、DeepSeekMathはAIにおける数学的推論の境界を押し広げるだけでなく、これらの機能を世界中の研究者、教育者、開発者が利用できるようにします。これは、高度なAI機能を民主化し、その潜在的な応用を拡大するための重要な一歩となります。
汎用LLMと並行して、DeepSeekMathのような特殊モデルの継続的な開発は、AIシステムが幅広い知識と特定の分野における深い専門知識を組み合わせることができる未来を示唆しています。これは人間の専門家が行うこととよく似ています。このバランスの取れたアプローチは、最終的に、広範な理解と深い理解の両方を必要とする複雑な現実世界の問題に対処するのに最も効果的であることが証明される可能性があります。
D. Hendrycks、C. Burns、S. Kadavath、A. Arora、S. Basart、E. Tang、D. Song、およびJ. Steinhardt。MATHデータセットを使用した数学的な問題解決の測定。arXivプレプリントarXiv:2103.03874、2021年。
K. Cobbe、V. Kosaraju、M. Bavarian、M. Chen、H. Jun、L. Kaiser、M. Plappert、J. Tworek、J. Hilton、R. Nakanoら。数学の文章問題を解決するための検証者のトレーニング。arXivプレプリントarXiv:2110.14168、2021年。
A. Lewkowycz、A. Andreassen、D. Dohan、E. Dyer、H. Michalewski、V. Ramasesh、A. Slone、C. Anil、I. Schlag、T. Gutman-Soloら。言語モデルによる定量的推論問題の解決。AdvancesinNeuralInformationProcessingSystems、35:3843–3857、2022a。
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y. Wu, Y. K. Li, F. Luo, Y. Xiong, and W. Liang. Deepseek-coder: When the large language model meets programming – the rise of code intelligence, 2024.
ソース: Release Release v3.19.4 · RooCodeInc/Roo-Code
早速、Gemini Pro 06-05 モデルのサポートが来たので、切り替えています。
Gemini Pro 05-06 モデルでは使えなかった 推論を有効化 のオプションが使えるようになっていますね。
thinking モデルを別にするのではなく、オプションで切り替える方式になったのですね。
現在各社のモデルの数が多く、命名ルールもわかりにくいので、減らす方向の動きは嬉しいですね。
AIベンダーは5月の大半をAI関連の発表に費やし、ほぼすべてのカテゴリーに進出しました。しかし、注目すべきニュースはこれだけではありません。医師たちは、CRISPRを用いて、これまで治療不可能だった希少疾患を持つ赤ちゃんのDNAを修正しました。この治療が何年も効果があったかどうかは分かりませんが、赤ちゃんは順調に成長しているようです。また、あるスタートアップ企業が究極のニューラルネットワークを販売しています。これは生きた(培養された)ニューロンから作られ、ニューロンを数週間稼働させ続ける生命維持装置も備えています。これが本当に実現するかどうかはまだ分かりませんが、それでもAlphaGoにいつ勝てるようになるのか知りたいものです。
再注目は、Claude Sonnet 4 ですね。プログラミング支援のAI利用のAPIは順次検証しながら切り替えていっています。 今回のレポートには無かったですが、日本では Claude Sonnet 4 と同時期にリリースされた、Claude Code + Max プランでの「(ほぼ)定額CLI型コーディング支援」に注目が集まっているので、こちらもキャッチアップしておきたいですね。
インターネットは貴重な情報の宝庫ですが、正直に言うと、時に圧倒されてしまうこともあります。企業のウェブサイト、ブログ、ニュースレター、ソーシャルメディアの投稿、ポッドキャスト、動画、長文記事など、あらゆる情報をチェックするのは、まるでフルタイムの仕事のように感じるかもしれません。そんな時に便利なのが 、後で読むツール です!
後で読むアプリの本質は、個人的なコンテンツ保管庫、つまり時間をかける価値のある記事を保存し、洞察を振り返り、知識ベースを構築するためのキュレーションされたスペースです。しかし、その有用性にもかかわらず、過小評価されがちです。
後で読む優れたエクスペリエンスに何が期待できるかを詳しく見ていきましょう。
過去1ヶ月間のベスト記事がすべて揃っていて、旅行中にいつでも読める状態を想像してみてください。あるいは、業界トレンドの完全なアーカイブが、検索と注釈付きで完全に保存されている状態を想像してみてください。あるいは、Web上で自社ブランドが言及されているすべての箇所がタグ付けされ、参照用にファイル化されている状態を想像してみてください。適切な設定さえすれば、これは夢ではなく、日々のワークフローの一部になります。そして、Inoreaderはそれをすべて可能にします。
Inoreader はRSSリーダーとして知られている方も多いと思いますが、実は豊富な機能を備えた「後で読む」ソリューションとしても機能します。コンテンツを探すか保存するか、もう迷う必要はありません。Inoreader を使えば、その両方をシームレスに、1か所で行うことができます。
もう一度読みたい記事、保存しておきたいニュースレター、LinkedInの素敵な投稿など、すべて保存して後で読みましょう!Inoreaderのブラウザ拡張機能、モバイル共有、またはメールからInoreaderへ送信する機能を使えば、Web上のコンテンツをクリップできます。さらに、お手持ちのPDFやドキュメントをアップロードすれば、Inoreaderがそれらを読みやすいきれいな記事に変換してくれます。
広告、ポップアップ、雑然としたレイアウトは一切なし。Inoreaderは、あらゆるデバイスで一貫した読書体験を提供します。保存した記事、PDF、ソーシャルメディアの投稿など、どんなコンテンツを読むときでも、インターフェースは常にすっきりと整理されているので、コンテンツが際立ち、常に一歩先を行くことができます。
Inoreaderで、読書をより意識的に。重要なポイントをハイライトしたり、メモを残したり、記事に注釈を付けたりできます。さらに、InoreaderはAIツールもサポートしており、要約を抽出したり、読んだ内容に関する質問に答えたりできます。さらに、全文検索機能を使えば、考えやアイデアを見失うことはもうありません!
タグと「後で読む」キューを使って、コンテンツコレクションを整理しましょう。保存したアイテムは、元のコンテンツがウェブから削除されても引き続きアクセスできます。ルールを使えば、コンテンツがアカウントに届いた瞬間に自動的にタグ付け、共有、転送できます。すべてのコンテンツは検索可能で、簡単に取り出すことができ、必要な場所にすぐにアクセスできます。
すべてのコンテンツはウェブとモバイル間で同期されます。ノートパソコンで読書リストを作成して、外出先で読み進めることができます。Wi-Fiのない場所に行く予定でも、Inoreaderのオフラインモードを使えば、どこにいても読書を続けることができます。
後で読むサービスの多くは、コンテンツを探して保存するという手間をユーザーに求めています。しかし、Inoreaderなら、コンテンツがあなたのもとへやって来ます。お気に入りのブログやクリエイター、ニュースレターやパブリッシャー、YouTubeチャンネルなどをフォローしましょう。そして、フィードからワンクリックで最適なコンテンツを直接保存できます。最小限の労力で、よりスマートかつ迅速にライブラリを構築できる方法です。
Inoreaderは、価値あるコンテンツの収集と整理に最適で、常に最新情報を入手したいヘビーユーザー、研究者、そしてプロフェッショナルにとって理想的なパートナーです。邪魔にならないクロスデバイスインターフェースと、コンテンツ検索機能と「後で読む」機能がシームレスに統合されたInoreaderは、最適なコンテンツを見つけるだけでなく、いつでもどこでもコンテンツを最大限に活用するのに役立ちます。
Pocketの終了アナウンス後、自分は Inoreader を RSS 購読アプリとしてだけでなく、「後で読む」アプリとしても利用しています。但し、モバイルでの「後で読む」体験 (後で読み終わったよの処理) があまり良くなく、Web ブラウザでのみで使っています。
この使い方で、公式からの情報以外で、気づいた便利ポイントを下記にメモしておきます。もうちょっと嬉しかったポイントはあった気がしますが、すぐに思い出せる範囲での共有とさせてください。
あと、Webブラウザのみで、モバイルを捨てた背景も機会や余裕があれば、記事にしたいと思っています。
ソース: Release Release v3.19.3 · RooCodeInc/Roo-Code
Claude Code with Claude Max プランが、API従量課金なしで人気になっているようですね。余裕があれば少し浮気してみたいですね。
ソース: Release Release v3.19.2 · RooCodeInc/Roo-Code
自分はこのバグフィックスのスピードについていけていないですが、いつかコントリビュートしてみたいですね。
ソース: Release Release v3.19.1 · RooCodeInc/Roo-Code
Bedrockのサポートやバグ修正が早いですね。自分はBedrockを通してRoo Codeを使ってないのですが、Enterpriseではよく使われているんですかね。ちょっと調べてみようかなと。